[알고리즘 기초] 정렬 - 버블 정렬, 퀵 정렬, 병합 정렬, std::sort등
버블 정렬, 퀵 정렬, 합병 정렬, 그리고 C++ 표준 라이브러리 std::sort를 비교해보며 각 알고리즘의 특징과 장단점을 정리합니다. 알고리즘 공부를 위한 기초부터 실무에서 가장 많이 쓰이는 정렬 함수까지 한눈에 확인할 수 있습니다.
![[알고리즘 기초] 정렬 - 버블 정렬, 퀵 정렬, 병합 정렬, std::sort등](/content/images/size/w2000/2025/09/photo-1510511459019-5dda7724fd87-1.jpg)
정렬(Sorting)이란?
정렬은 데이터를 크기 순서대로(오름차순 / 내림차순) 재배치 하는 것을 의미한다. 정렬에 사용되는 알고리즘은 여러가지가 있지반 본문에서는 3가지 정도 정리해 보았다.
- 버블 정렬 (Bubble Sort)
- 퀵 정렬 (Quick Sort)
- 합병 정렬(Merge Sort)
버블 정렬 (Bubble Sort)
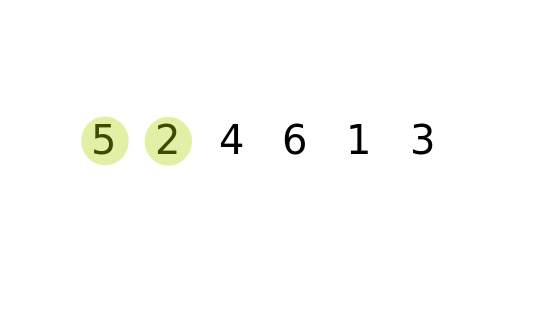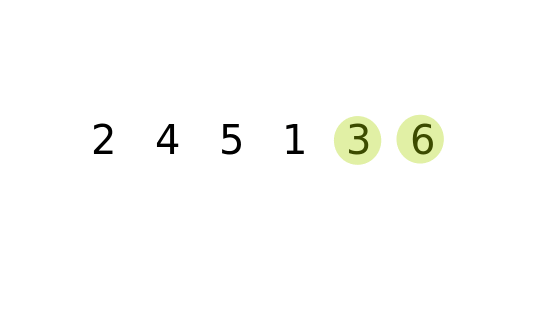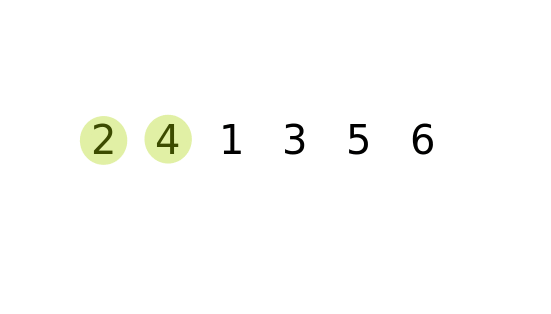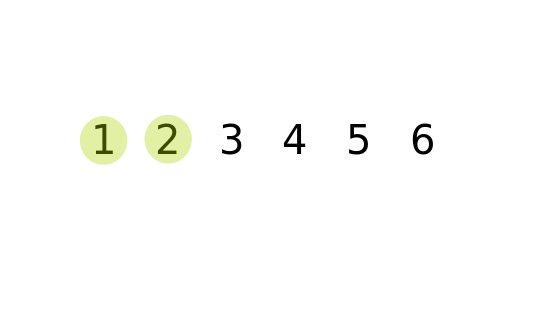
가장 단순한 정렬 방법이지만, 시간 복잡도가 가장 높다. 아이디어는 바로 옆에 있는 원소와 비교해서 자리를 계속 바꾸는 방식이다. 시간 복잡도는 O(n²)이기 때문에 데이터 크기가 커지면 비효율적이다.
구현은 다음과 같이 할 수 있다.
// Bubble Sort
// 아이디어: 인접한 두 원소를 비교해서 순서가 잘못되면 교환.
// n번 반복하면서 가장 큰 값이 뒤로 밀려남.
void bubbleSort(std::vector<int> &arr)
{
size_t n = arr.size();
for (auto i = 0; i < n - 1; ++i)
{
for (auto j = 0; j < n - i - 1; ++j)
{
if (arr[j] > arr[j + 1])
{
auto tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}bubble sort
퀵 정렬 (Quick Sort)
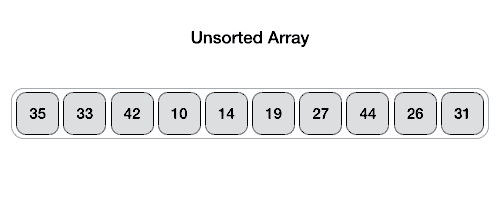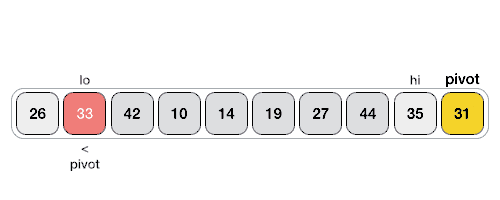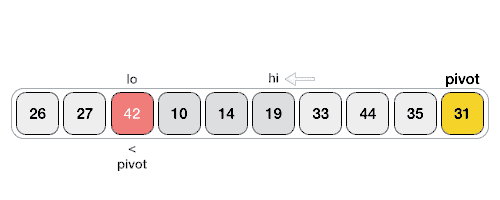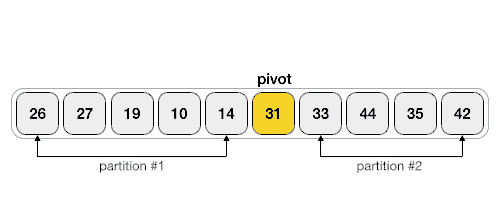
명칭대로 빠른 정렬을 수행할 수 있는 알고리즘이다. 배열 내에서 기준 (Pivot)을 잡고, 작은 값은 왼쪽으로, 큰 값은 오른쪽으로 나누는 방식을 재귀적으로 수행하는 방식이다.
void swap(int &a, int &b)
{
auto tmp = a;
a = b;
b = tmp;
}
// Quick Sort
// 아이디어: pivot을 기준으로 작은 값/큰 값으로 분할 → 각각 재귀 정렬.
// 평균 O(n log n), 최악 O(n^2).
void quickSort(std::vector<int> &arr, int left, int right)
{
if (left >= right)
{
return;
}
// 1. Pivot 정하기
auto pivot = arr[(left + right) / 2];
// 2. 양쪽에서 i, j 포인터 이동
int i = left;
int j = right;
while (i <= j)
{
while (arr[i] < pivot)
{
i++;
}
while (arr[j] > pivot)
{
j--;
}
if (i <= j)
{
swap(arr[i], arr[j]);
i++;
j--;
}
}동작 원리
- pivot: 기준점. 배열을 pivot 기준으로 작은 값 / 큰 값으로 나눔.
- 흔히
arr[left],arr[right],arr[(left+right)/2]중 하나를 사용. (left+right)/2를 많이 씀 → 평균적으로 괜찮음.
- 흔히
- i 포인터: 왼쪽에서 출발 → pivot보다 큰 원소 만나면 멈춤.
- j 포인터: 오른쪽에서 출발 → pivot보다 작은 원소 만나면 멈춤.
- swap: i ≤ j면 arr[i], arr[j] 교환.
- 포인터 교차가 끝나면 (i > j)
- 왼쪽 구간 [left, j]
- 오른쪽 구간 [i, right]
재귀 호출.
시간 복잡도는 평균 O(n log n)이며, 최악은 버블 정렬과 같은 O(n²)가 될 수도 있다.
합병 정렬 (Merge Sort)
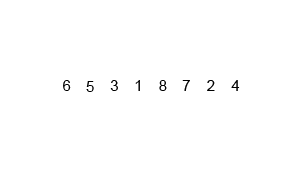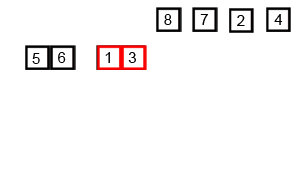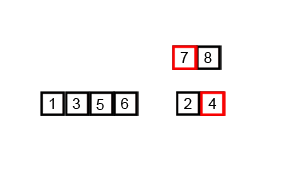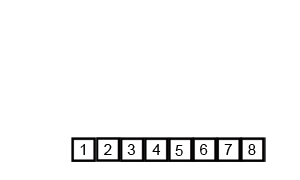
배열을 반씩 나누고 정렬한 뒤, 병합을 수행하는 알고리즘이다. 시간 복잡도는 항상 O(n log n)이지만, 메모리를 추가로 사용한다는 단점이 있다.
아이디어
"분할 정복(Divide and Conquer)" 방식
- 배열을 반으로 나눈다.
- 각각 재귀적으로 정렬한다.
- 두 개의 정렬된 배열을 병합(merge) 하여 하나의 정렬된 배열로 만든다.
특징
- 시간 복잡도: 항상 O(n log n)
- 공간 복잡도: O(n) (추가 메모리 필요)
- 안정 정렬(stable): 같은 값의 상대적 순서를 보존
void merge(std::vector<int> &arr, int left, int mid, int right)
{
int n1 = mid - left + 1; // 왼쪽 크기
int n2 = right - mid; // 오른쪽 크기
std::vector<int> L(n1);
std::vector<int> R(n2);
for (int i = 0; i < n1; i++)
{
L[i] = arr[left + i];
}
for (int j = 0; j < n2; j++)
{
R[j] = arr[mid + 1 + j];
}
int i = 0, j = 0, k = left;
// 두 배열을 비교하며 작은 값을 arr에 채움
while (i < n1 && j < n2)
{
if (L[i] <= R[j])
{
arr[k++] = L[i++];
}
else
{
arr[k++] = R[j++];
}
}
// 남은 값들 복사
while (i < n1)
{
arr[k++] = L[i++];
}
while (j < n2)
{
arr[k++] = R[j++];
}
}
void mergeSort(std::vector<int> &arr, int left, int right)
{
if (left >= right)
{
return;
}
int mid = left + (right - left) / 2;
// 분할
mergeSort(arr, left, mid);
mergeSort(arr, mid + 1, right);
// 병합
merge(arr, left, mid, right);
}std::sort
std::sort는 c++ 표준 라이브러리에서 제공하는 정렬 함수로 주어진 구간의 원소를 기본 오름차순으로 정렬한다. 알고리즘 공부 목적 이외에는 사실 정렬 알고리즘을 직접 구현하기 보단 이 함수를 사용하는 것이 훨씬 더 안전하고 효율적이다.
std::sort는 내부적으로 Introsort라는 하이브리드 방식을 사용하기 때문에 평균적으로는 퀵 정렬 수준의 빠른 성능을 내면서도, 최악의 경우에는 힙 정렬로 전환하여 O(n log n)의 시간 복잡도를 보장한다. 또한 작은 구간에서는 삽입 정렬을 이용해 캐시 친화적 성능을 낸다.
이러한 특성 덕분에 일반적인 상황에서는 직접 구현한 정렬보다 빠르며, 메모리 사용량도 최소화되어 실무 환경에서 범용적으로 쓰기에 적합하다.
다만 값이 같은 원소의 상대적 순서를 반드시 유지하지는 않기 때문에, 안정 정렬이 필요하다면 std::stable_sort를 선택하는 것이 더 적절하다.
기본 문법
std::sort(시작_반복자, 끝_반복자);
[시작_반복자, 끝_반복자)구간을 오름차순으로 정렬- 예:
vector<int> arr = {3, 1, 4};
사용자 정의 비교함수
std::sort는 세 번째 인자로 비교 함수(Comparator)를 받을 수 있다. 이를 사용하면 내림차순 정렬이나, 사용자가 원하는 방식대로 정렬을 구현할 수 있다.
#include <algorithm> // std::sort가 정의된 헤더
#include <vector>
#include <iostream>
// 사용자 정의 비교함수
bool cmp(int a, int b)
{
return a > b; // 큰 값이 앞에 오도록 (내림차순)
}
int main()
{
std::vector<int> arr = {3, 1, 4};
// 내림차순 정렬
std::sort(arr.begin(), arr.end(), cmp);
for (int x : arr) std::cout << x << " ";
// 출력: 4 3 1
}
람다 표현식
모던 c++애서는 람다 표현식을 활용해서 간편하게 사용자 정의 비교 함수를 작성할 수 있다.
std::vector<int> arr = {3, 1, 4};
std::sort(arr.begin(), arr.end(), [](int a, int b) {
return a > b; // 내림차순
});
구조체 / 객체 배열 정렬
사용자 정의 비교함수를 정의할 수 있기 때문에 단순한 정수 배열 뿐만 아니라 구조체나 객체의 배열에서도 사용할 수 있다.
struct Student
{
std::string name;
int score;
};
std::vector<Student> v = {{"Kim", 80}, {"Lee", 95}, {"Park", 70}};
// 점수 기준 내림차순
std::sort(v.begin(), v.end(), [](const Student &a, const Student &b) {
return a.score > b.score;
});
요약
| 알고리즘 | 시간 복잡도 (평균 / 최악) | 공간 복잡도 | 안정 정렬 여부 | 특징 / 비고 |
|---|---|---|---|---|
| 버블 정렬 | O(n²) / O(n²) | O(1) | ✔ 안정적 | 구현이 단순하지만 가장 비효율적. 알고리즘 학습용. |
| 퀵 정렬 | O(n log n) / O(n²) | O(log n) (재귀 스택) | ✘ 불안정 | 평균적으로 매우 빠름. 피벗 선택이 성능 좌우. 동치 값 많으면 성능 저하. |
| 합병 정렬 | O(n log n) / O(n log n) | O(n) | ✔ 안정적 | 항상 O(n log n), 대규모 데이터에서도 안정적. 메모리 추가 필요. |
| std::sort | O(n log n) / O(n log n) | O(1) | ✘ 불안정 | C++ 표준 라이브러리 제공. 내부적으로 Introsort(퀵+힙+삽입 혼합). 실무 최적 선택. |
관련 문제

